|
Animesh Sinha I'm a senior staff researcher at Meta Superintelligence Labs in Menlo Park, where I work on agentic multimodal generation. At Meta, I was a founding member of the Generative AI org in 2023, where I led early work on image and video generation, and later personalized media generation at scale. I have also worked on object recognition, retrieval, and vision-language representation learning. I received my Master's degree in Computer Science and Statistics from Purdue University in 2018, and my Bachelor's degree in Computer Science from IIT Kharagpur in 2014. Email / Google Scholar / GitHub / LinkedIn
|

|
ProductI have led the development and launch of models powering products across all Meta surfaces, spanning image understanding, retrieval, image generation and editing, and video generation. |
|
Swap People
2025 |
|
Imagine Yourself
2024 |
|
AI Stickers
2023 |

|
AI for Shopping
2021 |

|
Shop Any Photo
2020 |
ResearchMy work focuses on controllable media generation, multimodal reasoning, personalization, and foundation models for image and video. |

|
Muse Image & Muse Video
Meta Superintelligence Labs (Core Contributor) Meta AI Blog, 2026 Blog Image and video generation models developed by Meta Superintelligence Labs for creation, editing, tool use, and native-audio video generation. |
|
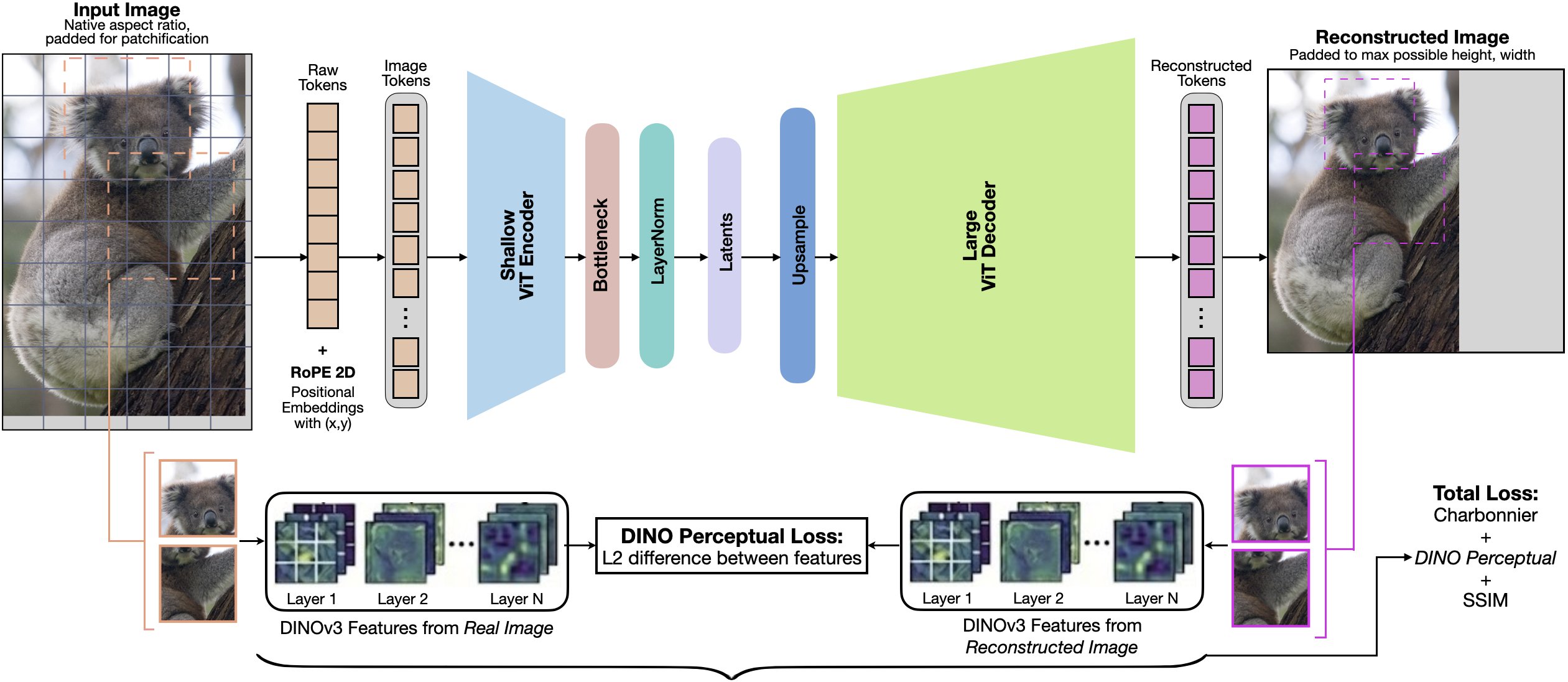
ViTok-v2: Scaling Native Resolution Autoencoders to 5 Billion Parameters
Philippe Hansen-Estruch, Jiahui Chen, Vivek Ramanujan, Orr Zohar, Yan Ping, Animesh Sinha, Markos Georgopoulos, Edgar Schoenfeld, Ji Hou, Felix Juefei-Xu, Sriram Vishwanath, Ali Thabet ICML, 2026 PDF / Project / Code Native-resolution vision autoencoders scaled to 5B parameters for high-fidelity reconstruction and efficient downstream generation. |
|
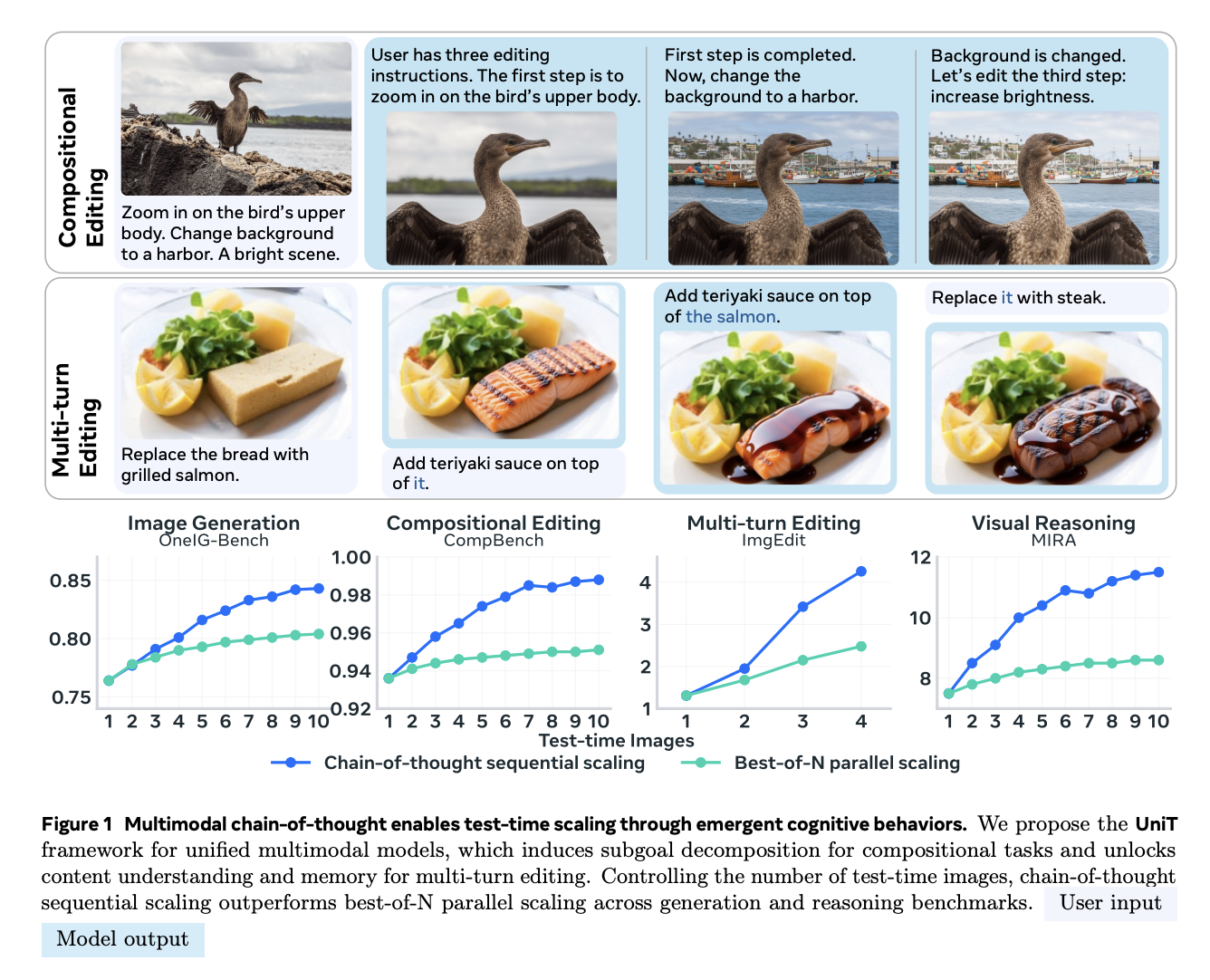
UniT: Unified Multimodal Chain-of-Thought Test-time Scaling
Leon Liangyu Chen, Haoyu Ma, Zhipeng Fan, Ziqi Huang, Animesh Sinha, Xiaoliang Dai, Jialiang Wang, Zecheng He, Jianwei Yang, Chunyuan Li, Junzhe Sun, Chu Wang, Serena Yeung-Levy, Felix Juefei-Xu CVPR, 2026 PDF / Project A multimodal chain-of-thought framework for scaling test-time reasoning across unified modalities. |
|
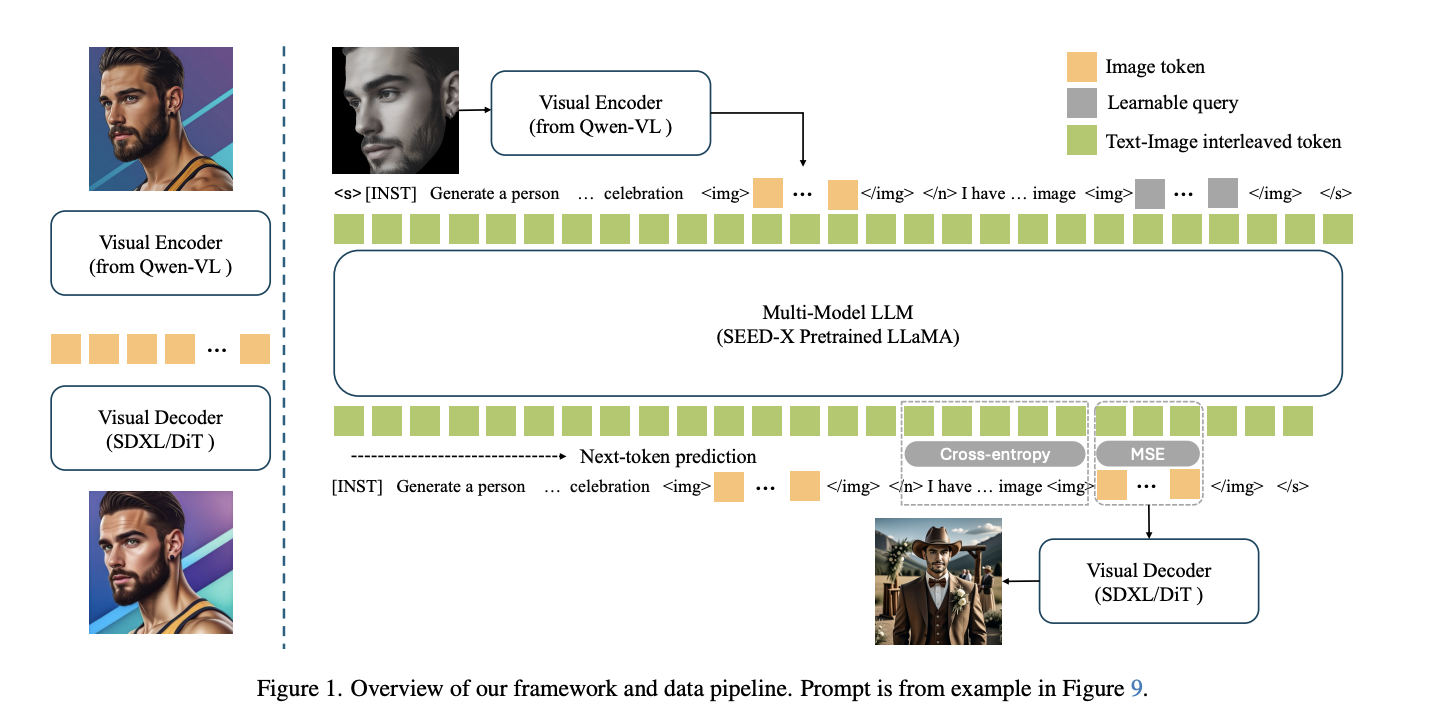
Conversational Image Generation: Towards Multi-Round Personalized Generation with Multi-Modal Language Models
Haochen Zhang, Animesh Sinha, Felix Juefei-Xu, Haoyu Ma, Kunpeng Li, Zhipeng Fan, Xiaoliang Dai, Tingbo Hou, Peizhao Zhang, Zecheng He WACV, 2026 Personalized image generation through multi-round conversational interaction with multimodal language models. |
|
|
MoCha: Towards Movie-Grade Talking Character Synthesis
Cong Wei, Bo Sun, Haoyu Ma, Ji Hou, Felix Juefei-Xu, Zecheng He, Xiaoliang Dai, Luxin Zhang, Kunpeng Li, Tingbo Hou, Animesh Sinha, Peter Vajda, Wenhu Chen NeurIPS, 2025 (Spotlight) PDF / Project Talking character synthesis aimed at movie-grade visual fidelity and control. |
|
|
Movie Weaver: Tuning-Free Multi-Concept Video Personalization with Anchored Prompts
Feng Liang, Haoyu Ma, Zecheng He, Tingbo Hou, Ji Hou, Kunpeng Li, Xiaoliang Dai, Felix Juefei-Xu, Samaneh Azadi, Animesh Sinha, Peizhao Zhang, Peter Vajda, Diana Marculescu CVPR, 2025 PDF / Project Video personalization without subject-specific tuning by anchoring prompts to multiple concepts. |
|
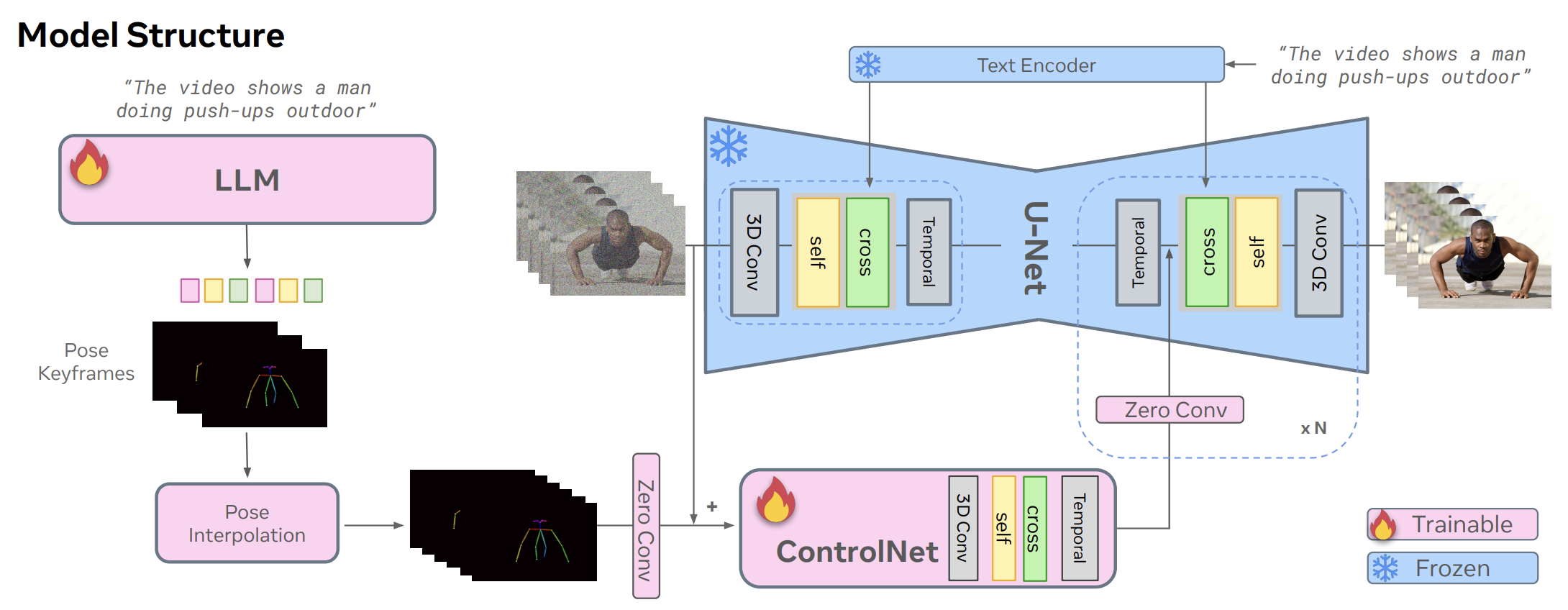
DirectorLLM for Human-Centric Video Generation
Kunpeng Song, Tingbo Hou, Zecheng He, Haoyu Ma, Jialiang Wang, Animesh Sinha, Sam Tsai, Yaqiao Luo, Xiaoliang Dai, Li Chen, Xide Xia, Peizhao Zhang, Peter Vajda, Ahmed Elgammal, Felix Juefei-Xu BMVC, 2025 Human-centric video generation directed with language models and structured control. |
|
|
Movie Gen: A Cast of Media Foundation Models
Movie Gen team (Led Video Personalization) arXiv, 2024 PDF / Dataset / Blog Foundation models for coherent image and video generation, editing, and evaluation. |

|
Imagine Yourself: Tuning-Free Personalized Image Generation
Zecheng He, Bo Sun, Felix Juefei-Xu, Haoyu Ma, Ankit Ramchandani, Vincent Cheung, Siddharth Shah, Anmol Kalia, Harihar Subramanyam, Alireza Zareian, Li Chen, Ankit Jain, Ning Zhang, Peizhao Zhang, Roshan Sumbaly, Peter Vajda, Animesh Sinha arXiv, 2024 PDF / Project Tuning-free personalized generation that preserves identity while remaining practical at scale. |

|
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
Animesh Sinha, Bo Sun, Anmol Kalia, Arantxa Casanova, Elliot Blanchard, David Yan, Winnie Zhang, Tony Nelli, Jiahui Chen, Hardik Shah, Licheng Yu, Mitesh Kumar Singh, Ankit Ramchandani, Maziar Sanjabi, Sonal Gupta, Amy Bearman, Dhruv Mahajan ECCV, 2024 PDF / Blog Latent diffusion models tailored for expressive, style-aware sticker generation. |

|
Context Diffusion: In-Context Aware Image Generation
Ivona Najdenkoska, Animesh Sinha, Abhimanyu Dubey, Dhruv Mahajan, Vignesh Ramanathan, Filip Radenovic ECCV, 2024 PDF / Project In-context image generation that uses example context to improve semantic and compositional fit. |

|
GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation
Shoufa Chen, Mengmeng Xu, Jiawei Ren, Yuren Cong, Sen He, Yanping Xie, Animesh Sinha, Ping Luo, Tao Xiang, Juan-Manuel Perez-Rua CVPR, 2024 PDF / Project An empirical study of diffusion transformers for both image and video generation tasks. |
|
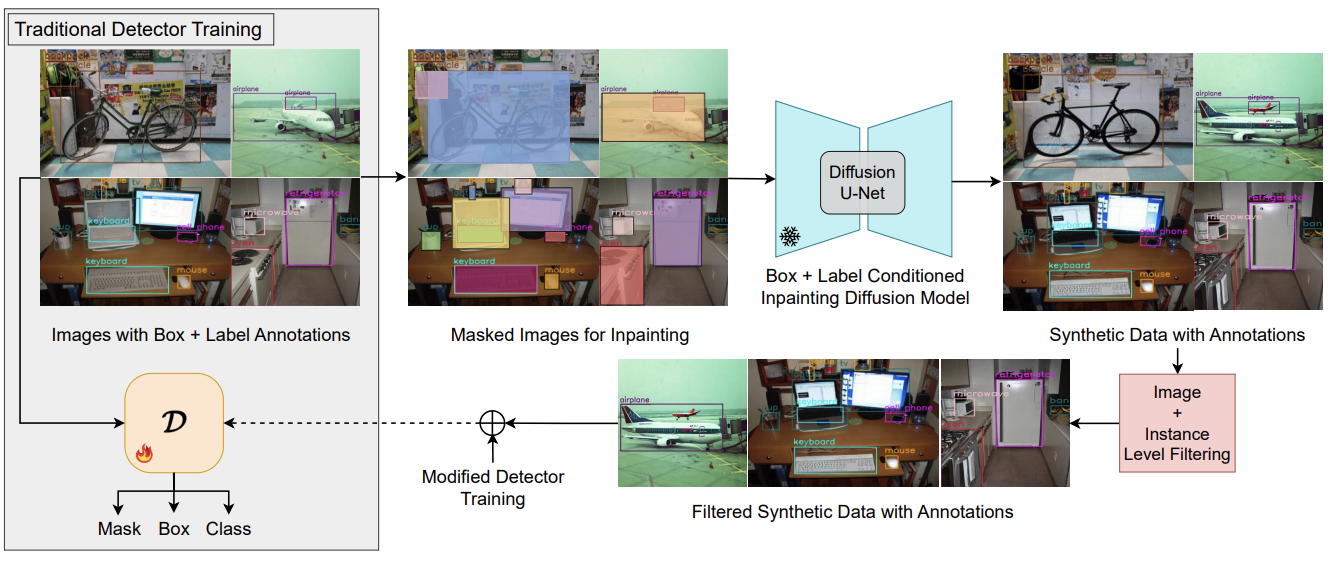
Gen2Det: Generate to Detect
Saksham Suri, Fanyi Xiao, Animesh Sinha, Sean Chang Culatana, Raghuraman Krishnamoorthi, Chenchen Zhu, Abhinav Shrivastava CVPRW, 2024 Using generation to strengthen downstream visual detection performance. |

|
Unaligned Video-Text Pre-training using Iterative Alignment
Arka Sadhu, Licheng Yu, Animesh Sinha, Hugo Chen, Ram Nevatia, Ning Zhang Video-language pre-training with iterative alignment for loosely paired multimodal data. |
|
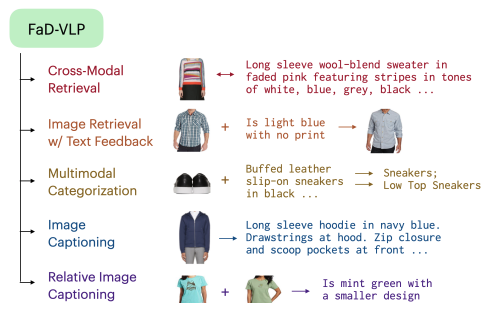
FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning
Suvir Mirchandani, Licheng Yu, Mengjiao MJ Wang, Animesh Sinha, Wenwen Jiang, Tao Xiang, Ning Zhang EMNLP, 2022 Unified pre-training for retrieval and captioning in fashion-focused vision-language settings. |
|
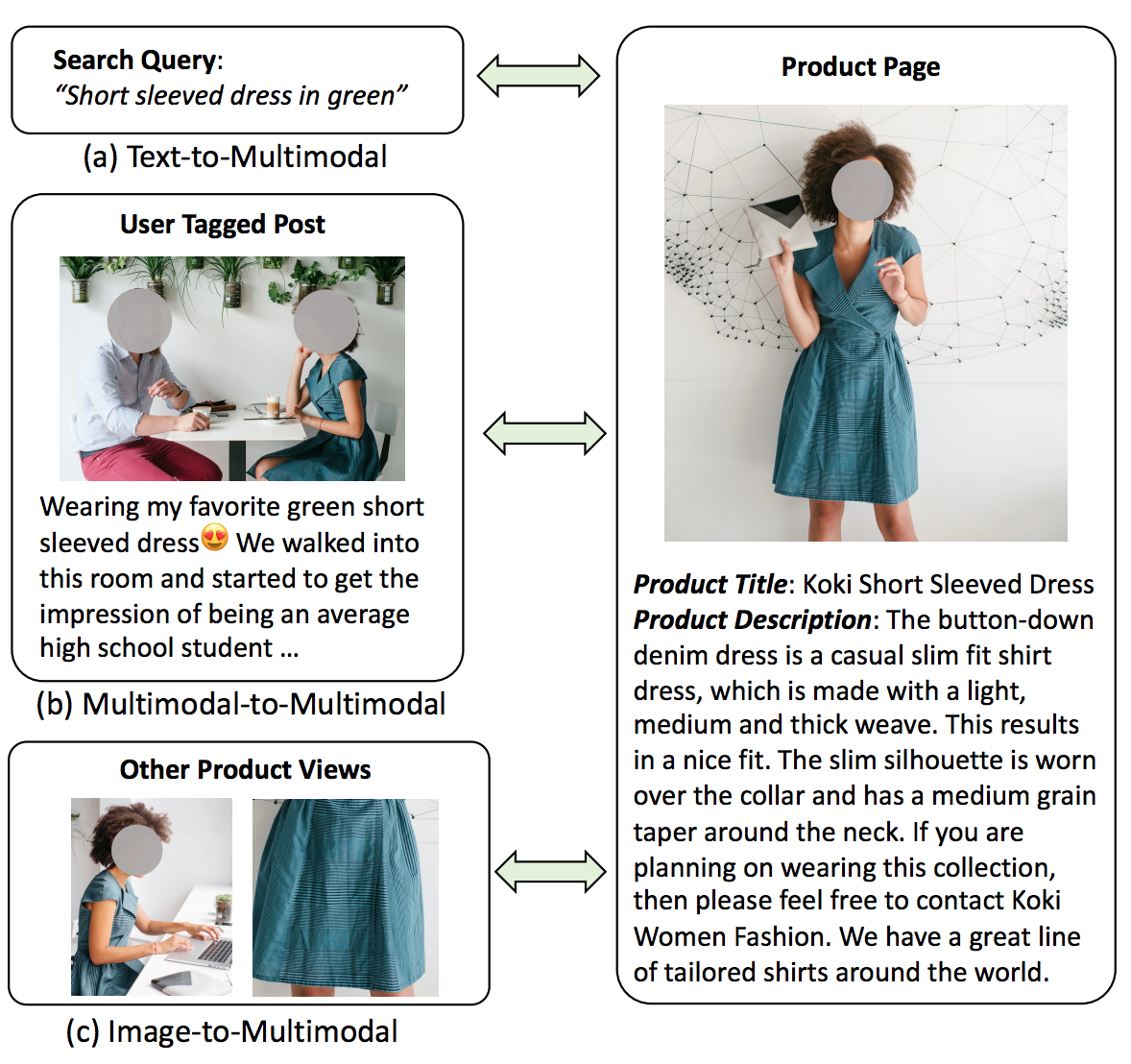
CommerceMM: Large-Scale Commerce MultiModal Representation Learning with Omni Retrieval
Licheng Yu, Jun Chen, Animesh Sinha, Mengjiao MJ Wang, Hugo Chen, Tamara L. Berg, Ning Zhang KDD, 2022 PDF / Blog Large-scale multimodal representation learning for commerce retrieval and ranking systems. |

|
Large-Scale Attribute-Object Compositions
Filip Radenovic, Animesh Sinha, Albert Gordo, Tamara Berg, Dhruv Mahajan arXiv, 2021 PDF / Blog Representation learning for scalable attribute-object composition understanding. |
|
|